圣者
精华
|
战斗力 鹅
|
回帖 0
注册时间 2019-1-7
|
本帖最后由 泰坦失足 于 2025-1-27 08:52 编辑
裸眼3D/云游戏/VR 这些已经被市场证明过消费者不买账的东西,刚开放5G和现在5G-A都有人blabla在那说必将是未来。我就纳闷了,之前有线网和WiFI时代,大家最后的选择还是2D屏幕玩本地游戏/看视频,为什么到了5G就能不一样。现在最流行最火爆的直播,你往20年前就能发现当时QQ群/XX网站自建的直播流服务已经在搞这些了. 当时大家心中都有这股需求,由于条件限制没被激发,移动互联网**降低了门槛。
life finds a way。云游戏这东西,全球用户就是不买账。哪怕是只有手机的用户,最后的选择也往往是玩本地运行手游。2025年了,绝大多数人都不自己架设RSS服务器,而是选择各种信息流推荐服务,也不自己本地下载,而是看在线视频。但是云游戏,至今仍是个新鲜玩意。再说云游戏/云VR要的带宽是最夸张的, 对有线/wifi还好说。5G时代,别的用户100G顶天了,一个云游戏/云VR用户用1T?打算向他们收多少钱
|
本帖子中包含更多资源
您需要 登录 才可以下载或查看,没有账号?立即注册
×
评分
-
查看全部评分
|


 发表于 2025-1-26 22:22
发表于 2025-1-26 22:22

 用他帮我出ai图的提示词差点把自己气死,就像个一根筋的刚毕业死大,要么就是点子王,要么就是报复性的删减你的要求
用他帮我出ai图的提示词差点把自己气死,就像个一根筋的刚毕业死大,要么就是点子王,要么就是报复性的删减你的要求 然后急眼了他就不反馈了
然后急眼了他就不反馈了 毕竟美国只在他需要的时候地广人稀,而且已经被开除美国人的底层确实不需要5G
毕竟美国只在他需要的时候地广人稀,而且已经被开除美国人的底层确实不需要5G
 科学的力量真伟大
科学的力量真伟大
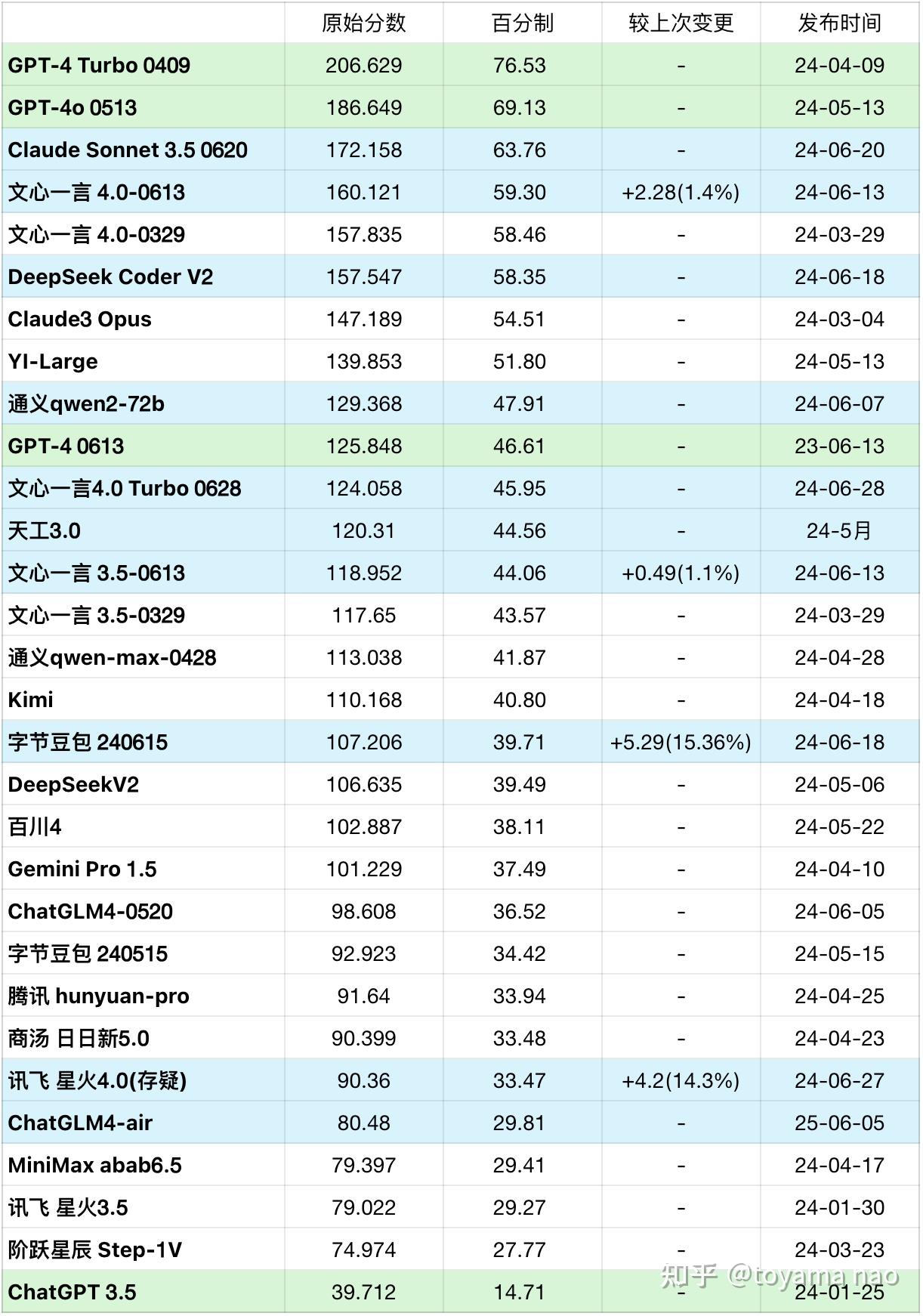
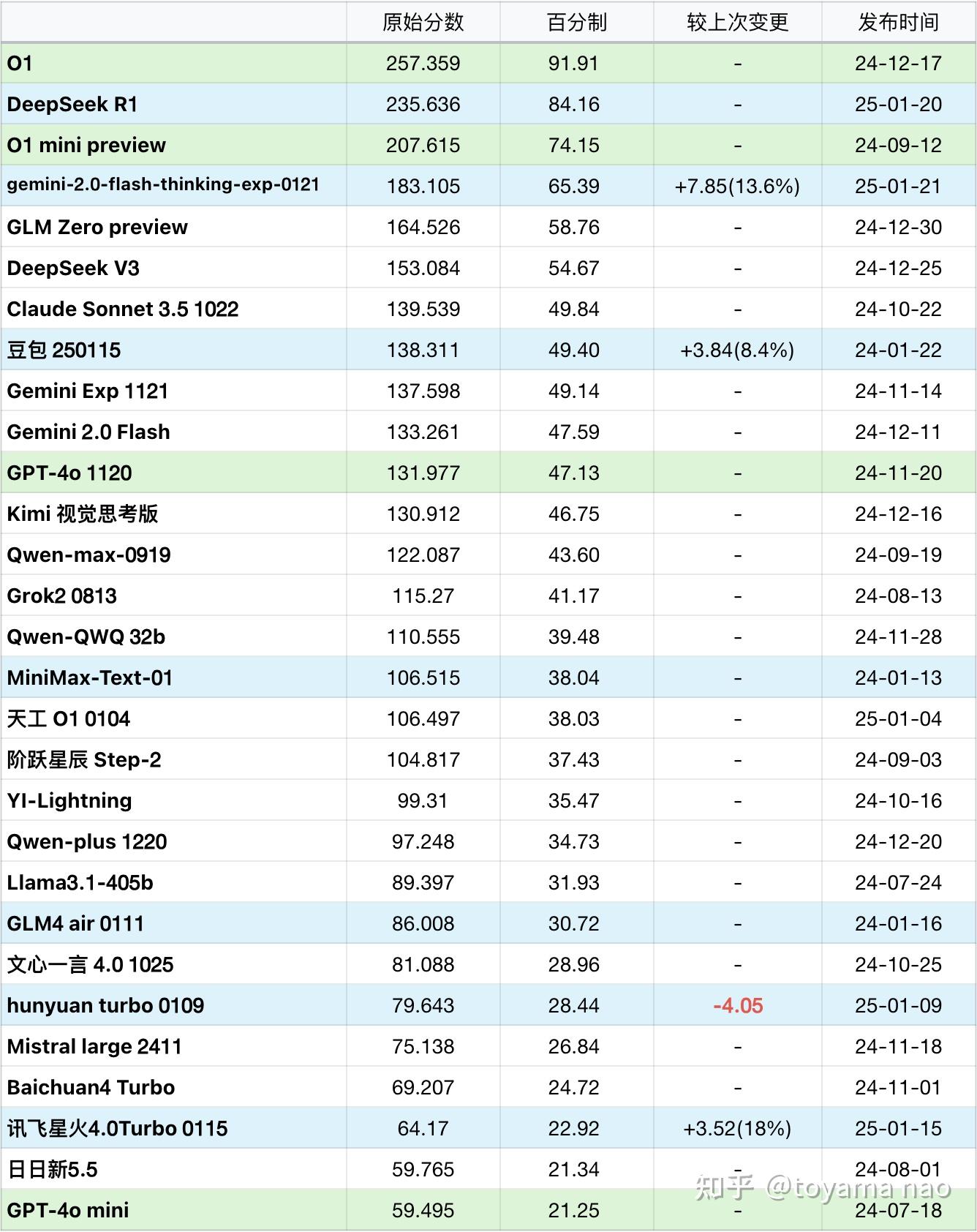
 不好意思之前对MoE了解肤浅了
不好意思之前对MoE了解肤浅了

