婆罗门
精华
|
战斗力 鹅
|
回帖 0
注册时间 2015-10-29
|
本帖最后由 orecheng 于 2024-7-12 19:22 编辑
https://www.cnblogs.com/bonne-chance/p/17413412.html
能用工具箱,干嘛要自己写
python的scipy.signal.find_peaks
- import numpy as np
- from scipy.signal import find_peaks
- import matplotlib.pyplot as plt
- def find_max_average_segment(arr, min_width=25, max_width=40, min_height_ratio=0.5):#区段最小值不得小于最大值的50%
- # 寻找峰值
- peaks, _ = find_peaks(arr, distance=min_width, width=[min_width, max_width])
-
- # 初始化最大平均值的区段信息
- max_avg = -np.inf
- max_segment = (None, None)
-
- # 遍历每个峰,找到符合条件的区段
- for peak in peaks:
- # 确定区段的左右边界
- left = max(0, peak - max_width // 2)
- right = min(len(arr), peak + max_width // 2)
-
- # 确保区段至少为min_width宽度
- if right - left < min_width:
- continue
-
- # 截取长度为max_width的区段
- segment = arr[left:right]
-
- # 计算区段平均值
- segment_avg = np.mean(segment)
-
- # 检查区段的最小值是否满足条件
- if np.min(segment) >= min_height_ratio * arr[peak]:
- # 更新最大平均值区段
- if segment_avg > max_avg:
- max_avg = segment_avg
- max_segment = (left, right)
-
- return max_segment
- def plot_selected_segments(arr, segments):
- plt.figure(figsize=(12, 6))
- plt.plot(arr, label='Array data')
-
- # 标记选中的区段
- for left, right in segments:
- plt.plot(range(left, right), arr[left:right], 'o', label=f'Segment {left}-{right}')
-
- plt.legend()
- plt.show()
- # 示例数组和参数
- np.random.seed(1)
- example_array = np.random.randn(500).cumsum()
- min_width = 25
- max_width = 40
- min_height_ratio = 0.5
- # 找到最大平均值区段
- segment = find_max_average_segment(example_array, min_width, max_width, min_height_ratio)
- # 如果找到了区段,则绘制图像
- if segment[0] is not None and segment[1] is not None:
- plot_selected_segments(example_array, [segment])
- else:
- print("没有找到符合条件的区段。")
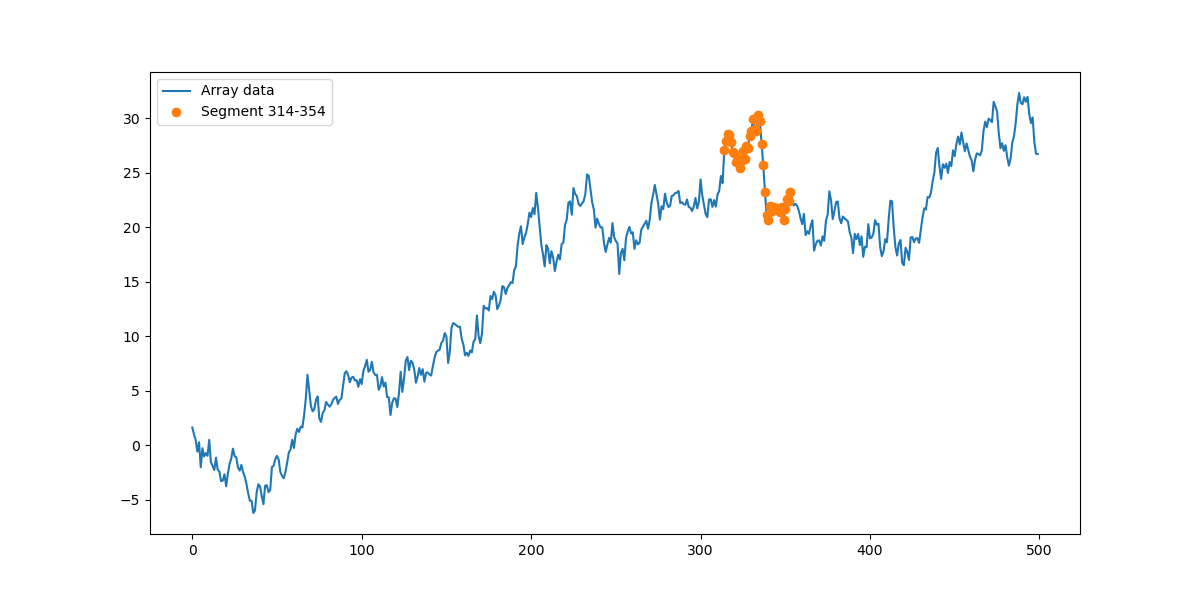
|
|


 发表于 2024-7-12 15:52
发表于 2024-7-12 15:52



 不过这个方法碰到已扫过的区间就中断应该可以很直观地做成O(n)
不过这个方法碰到已扫过的区间就中断应该可以很直观地做成O(n)