半肾
精华
|
战斗力 鹅
|
回帖 0
注册时间 2017-11-20
|
转自隔壁chip,写在前面:我想问牙膏厂的11代还有救嘛……
https://www.chiphell.com/forum.php?mod=viewthread&tid=2271639&extra=page%3D1&mobile=2之前的5600x和5800x的原稿撤掉了,链接暂时失效,不过图片依旧有效。如果你懒得看那么多图,请看以下三张总分即可,我在5950x中将所有项目的详细说明进行翻译(楼下指出不要跨图去比分数)
Native Performance
We are testing native arithmetic, SIMD and cryptography performance using the highest performing instruction sets (AVX2, FMA3, AVX, etc.). Zen3 supports all modern instruction sets including AVX2, FMA3 and even more like SHA HWA but not AVX-512.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest AMD and Intel drivers. 2MB “large pages” were enabled and in use. Turbo / Boost was enabled on all configurations. All mitigations for vulnerabilities (Meltdown, Spectre, L1TF, MDS, etc.) were enabled as per Windows default where applicable.
本机性能
我们使用了最高性能的指令集(avx2, FMA3, avx等等)测试了本机算法,单指令多数据流,加密性能。zen3支持所有现代指令集包括avx2, FMA3甚至sha,hwa,但不支持avx-512
测试结果解释:越大越好(单位GOPS, MB/s 等等)
测试环境:win10 x64,最新的amd intel驱动,启用2m的大页面。启用turbo/boost功能。windows默认已经将所有漏洞补丁打上了(熔断,幽灵,L1TF,MDS)

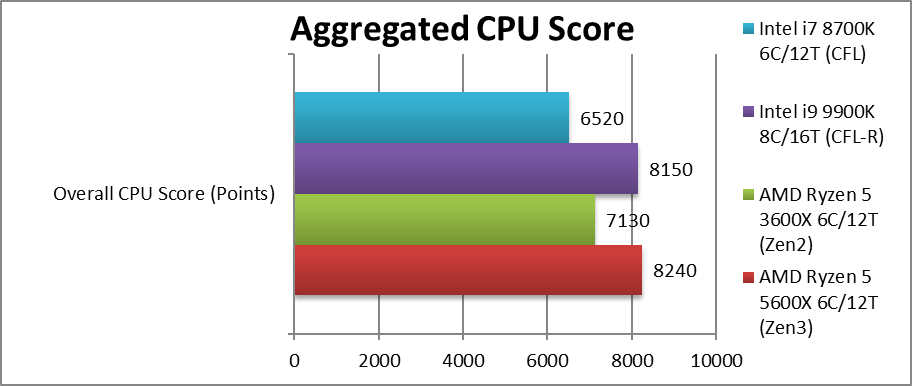
5600x篇 (性能增幅对比zen2)
算法 (arthmetic navie ) +15~26%
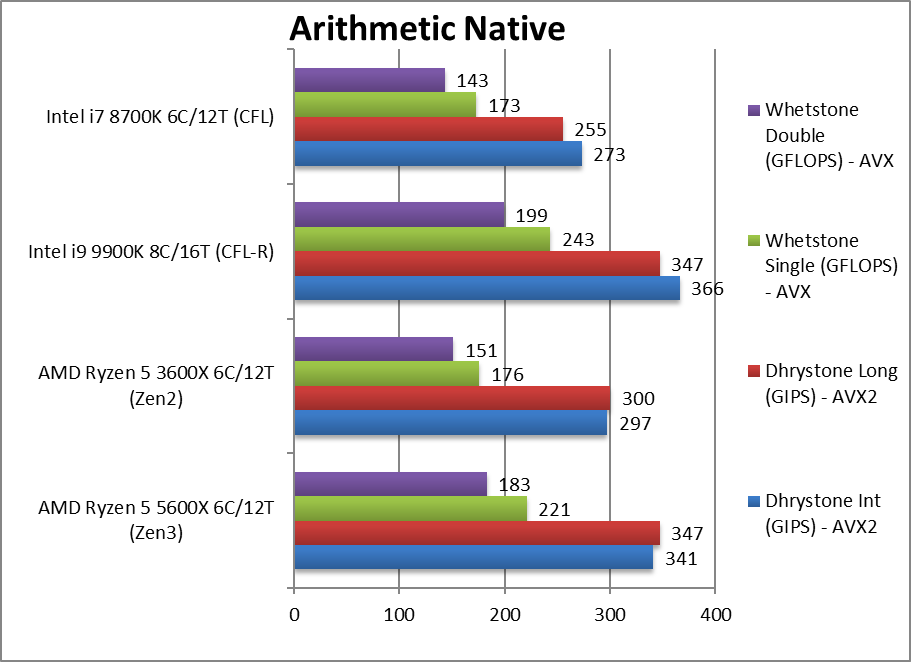
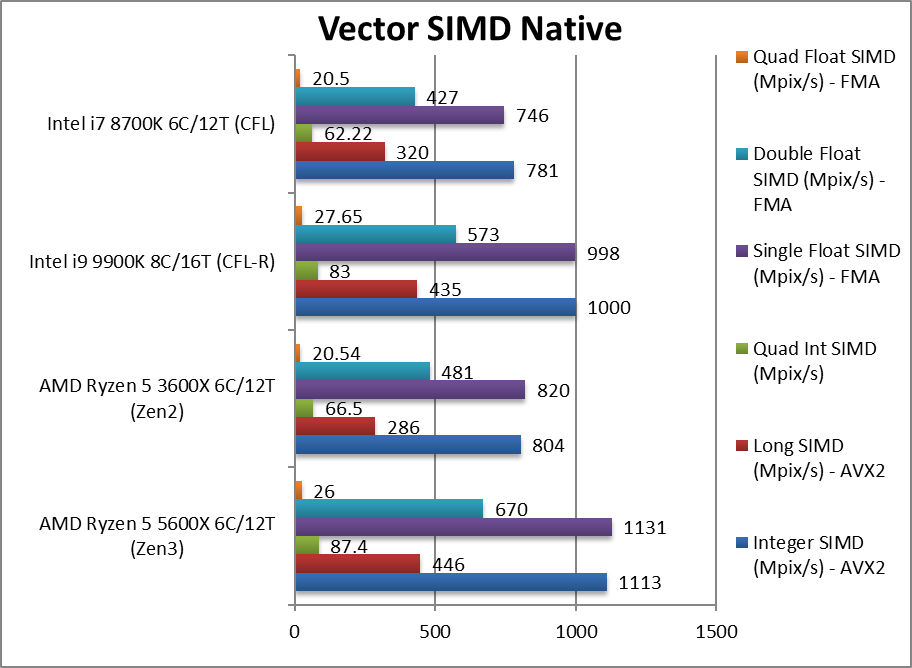
矢量单指令多数据流(vector simd native) +25-56%
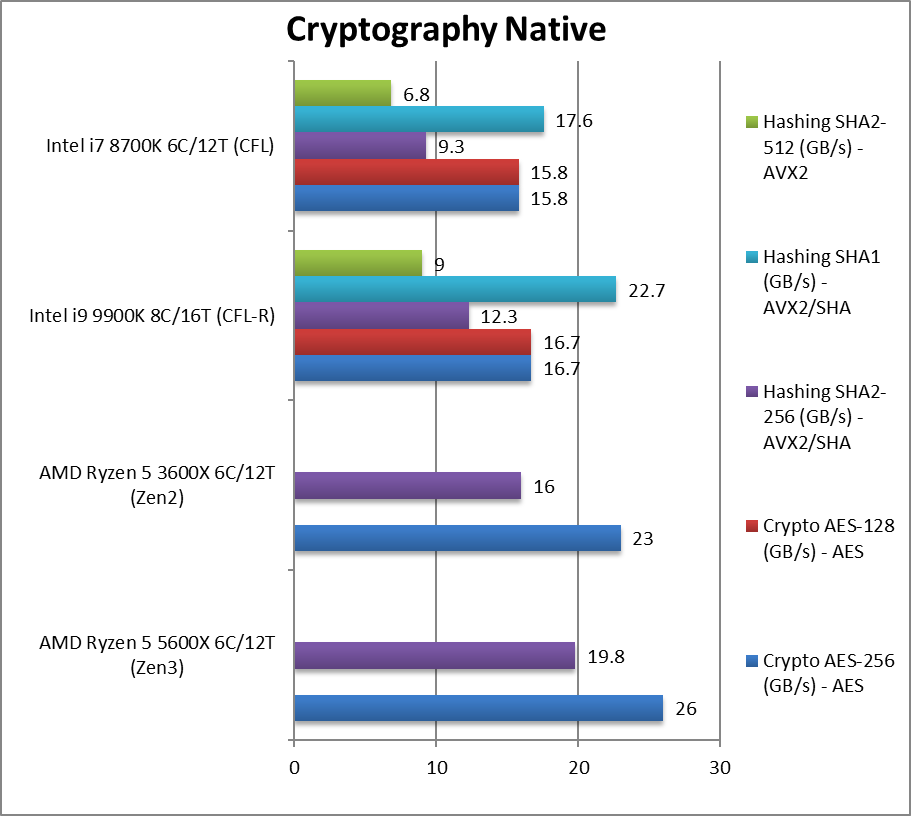
加密性能(crypography native) +13%~24%
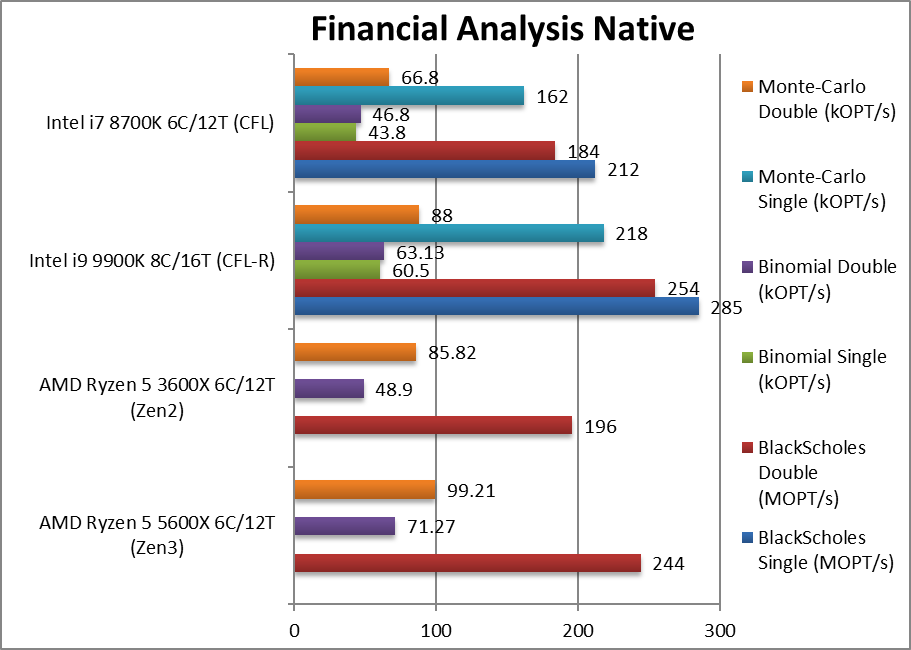
金融分析 (financial **ysis nativ) +16%~46%
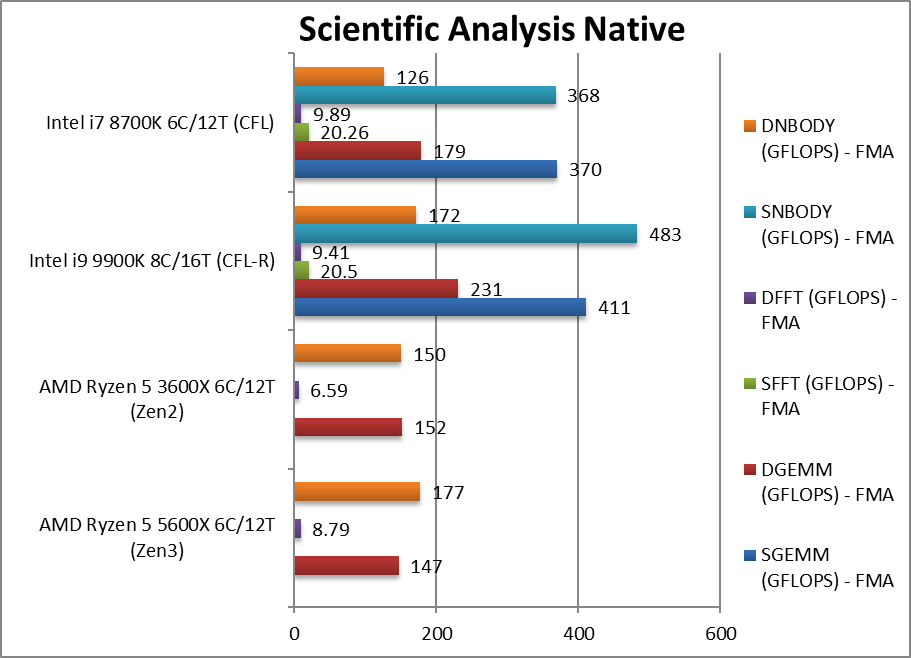
科学计算(scientific **ysis native) -3%~+33%
图像处理(image processing native) +29%~52%
总分(aggregated cpu score) +16% (秒了9900k,也许是因为牙膏有倒吸)
Executive Summary: Zen3 (X, 6-core) is ~15-40% faster than Zen2 (XT, 6-core) across all kinds of algorithms. We’ll give it 9/10.
总结:zen3比zen2在各种算法中快15%-40%,评分9/10
尽管在 Zen2 + Zen3 上没有重大架构更改(除了更大的 8 核单 CCX 布局(此处禁用了 2 个内核),因此统一了 L3 缓存),但在整个传统和高度矢量化的 SIMD 算法中,速度要快得多, 虽然在6核(又名5600X)的情况下,由于相比旧的Zen2(3600XT)其几乎相同的Turbo,它不能像5800x一样击败前辈,因为我们在其他评论看到。Zen2 XTs 性能太好
尽管如此,这足以超越英特尔的竞争,即使是旧的高端8核 i9 9900K,这是一个巨大的胜利 - 6核 i7 8700K望尘莫及。
同样,实际上它就像获得一个8核CPU,但价格是6核,尽管成本高于旧的CPU;这是一个很大的升级,特别是对于旧的 AM4 板可能仍在使用 Zen1/Zen® CPU(例如 1600,2600 左右)。在这个级别上,PCIe3 的性能(在 400,300 系列板上)很好,您得到的是一个相对便宜的系统,可以击败过去较旧的顶级系统。注意: 只要有一个 BIOS 更新可用, 或者你可以修改一个
和以前一样 – 如果您想要这些 Cpu 之一, 请确保现在购买甚至预购一个, 以避免失望
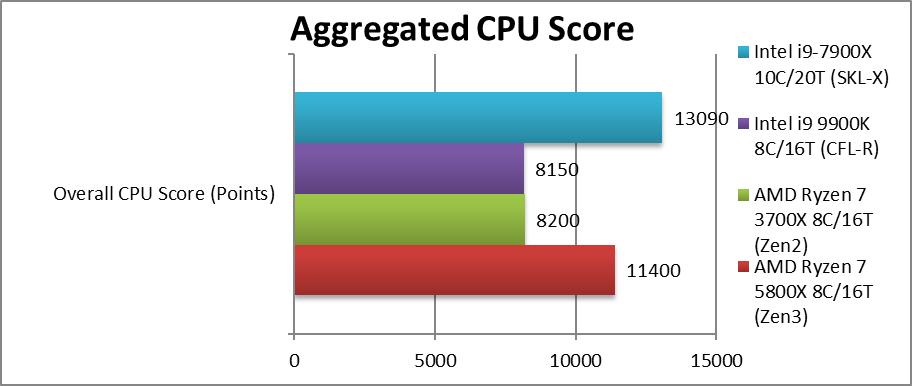
重头戏——5800x篇
注意:参与的7900x开启avx512进行对比
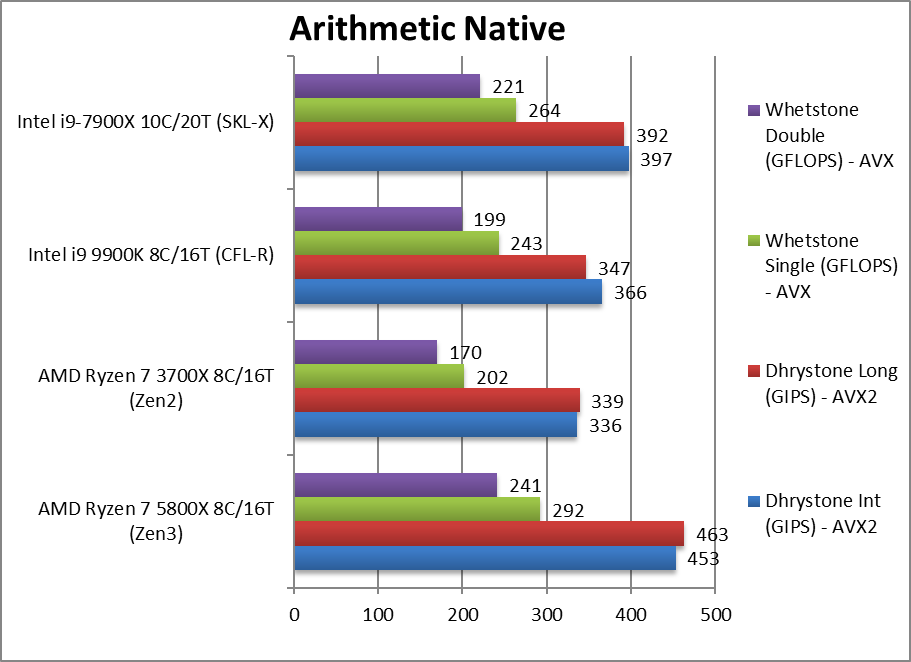
算法 (arthmetic navie ) +35~45%
矢量单指令多数据流(vector simd native) +25-60%
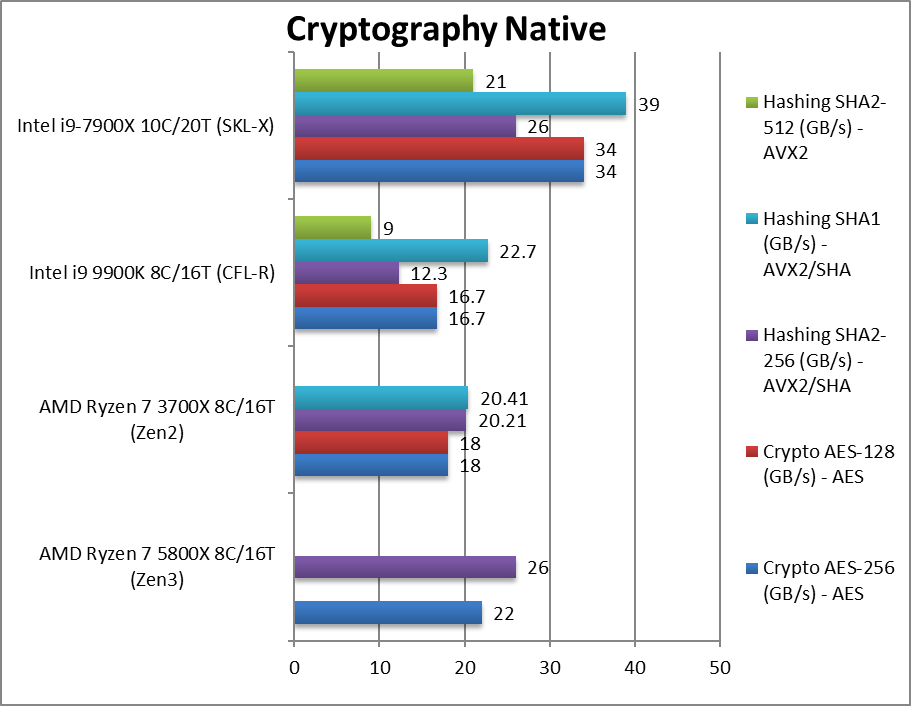
加密性能(crypography native) +22%~29%
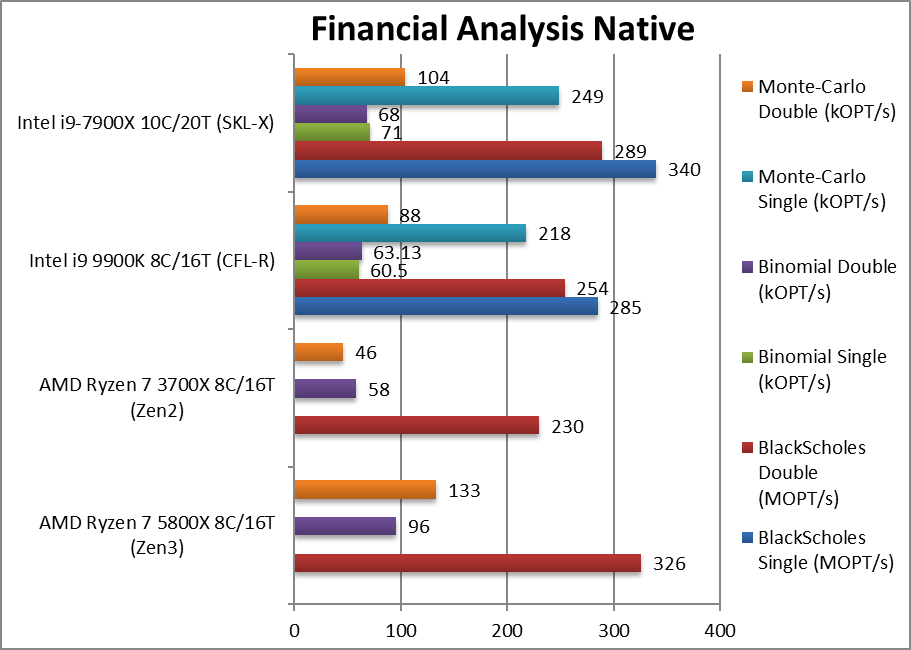
金融分析 (financial **ysis nativ) +42%~290%
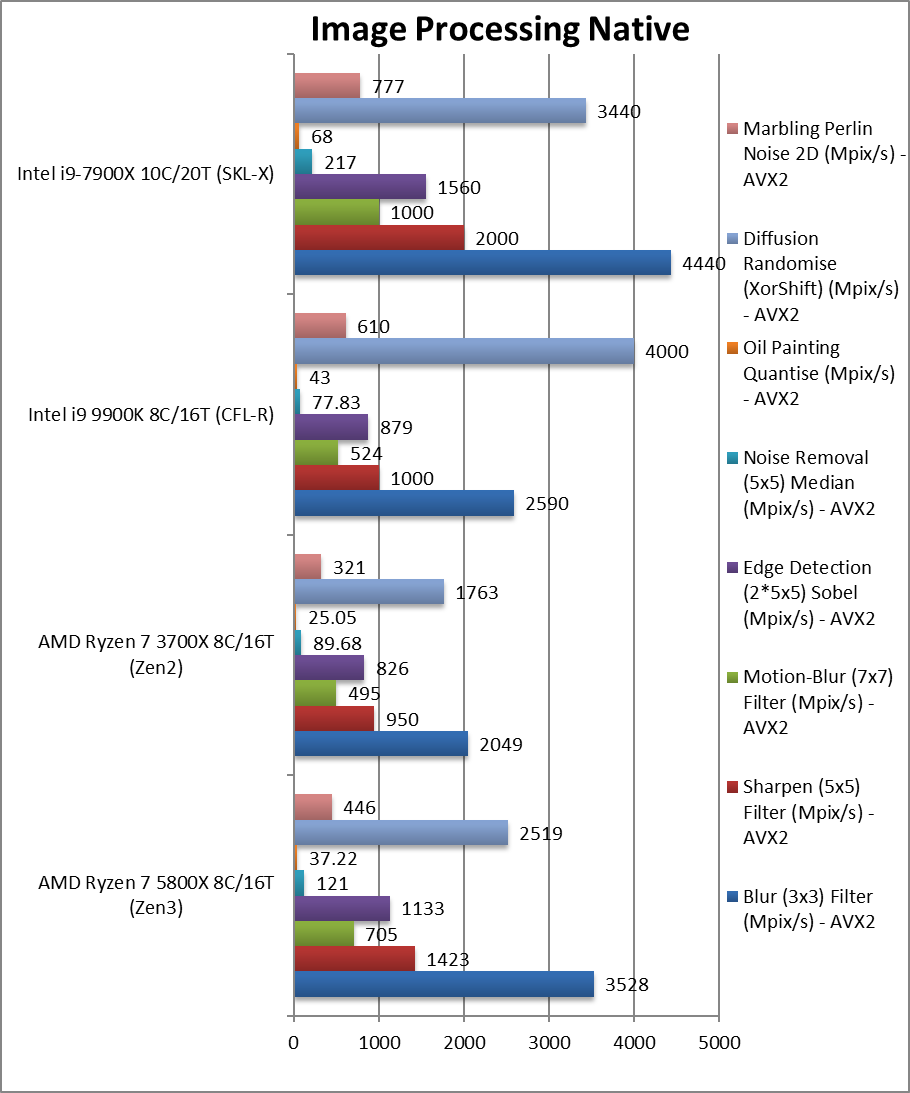
科学计算(scientific **ysis native) -20%~+42%
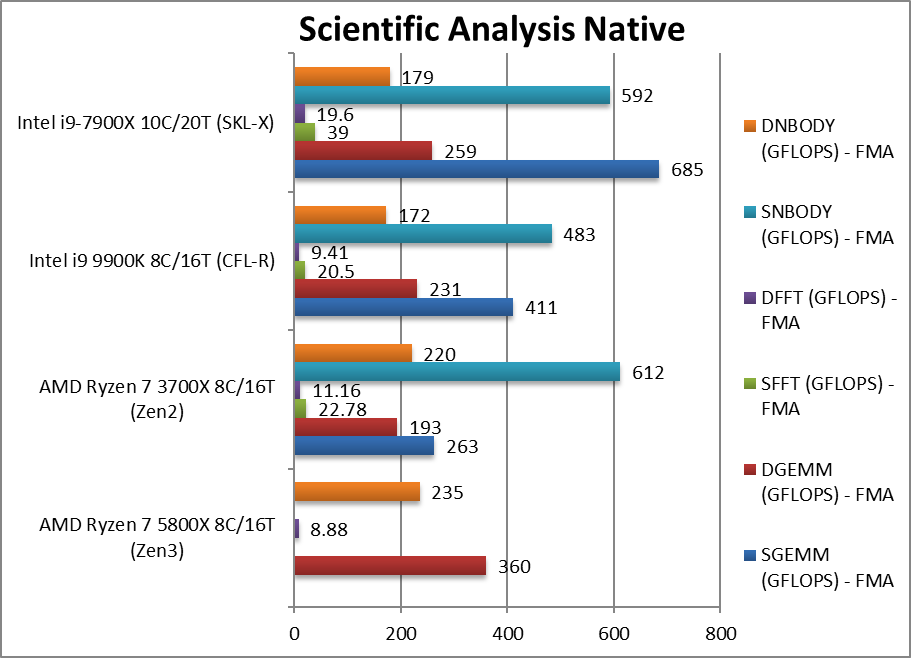
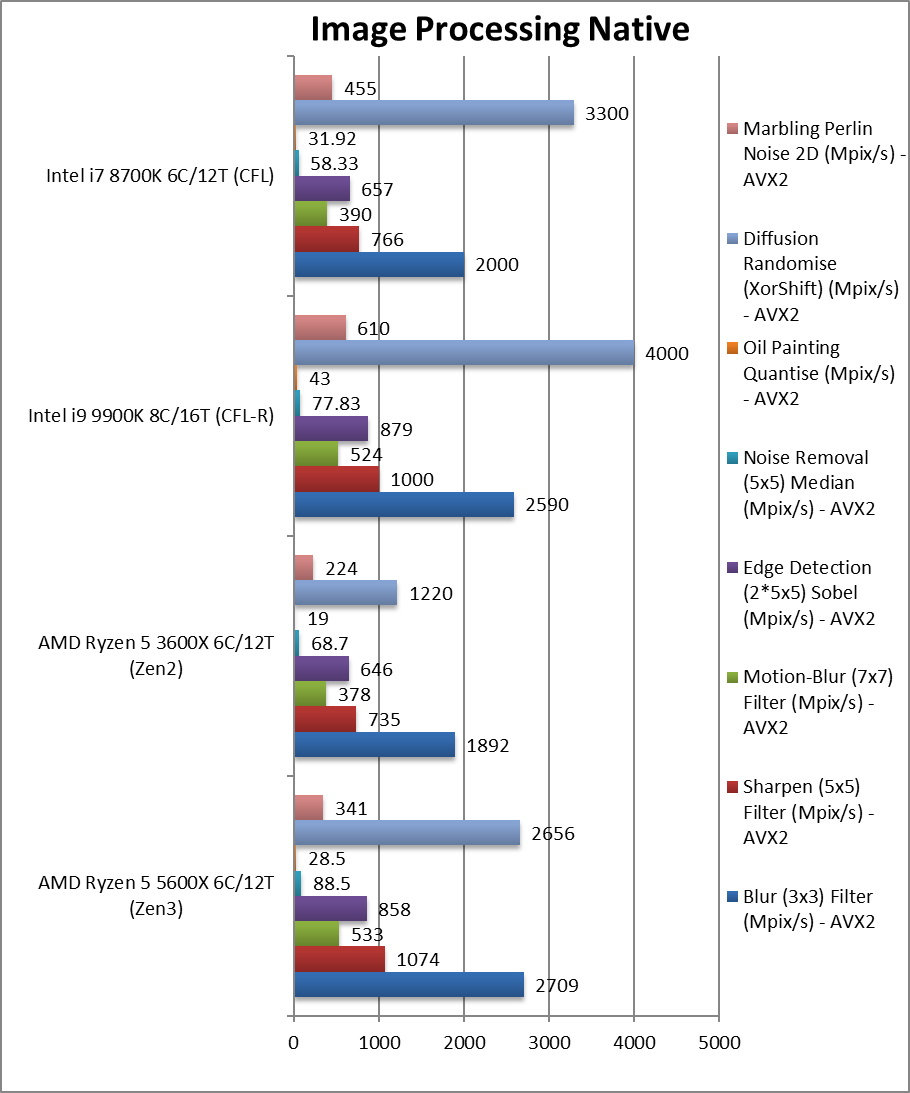
图像处理(image processing native) +35%~70%
总分(aggregated cpu score) +39% (没干过10c的7900x,你不得不说一旦avx512被调用intel的确很强)
Executive Summary: Zen3 (X, 8-core) is ~25-40% faster than Zen2 (X, 8-core) across all kinds of algorithms. We have to give it 10/10 overall!
总结:Zen3(X,8 核)在所有算法中比 Zen2(X,8 核)快 25-40。我们必须给它 10/10
尽管 Zen2 没有重大架构变化(除了较大的 8 核单 CCX 布局,因此统一 L3 缓存),Zen3 在传统和高度矢量化的 SIMD 算法中速度相当快,即使 AVX512 和更多内核相比(例如 10 核 SKL-X)也击败了竞争对手。甚至流式处理算法(内存绑定)也提高了 20%多。我们当然没想到表现会这么好。
实际上,这就像获得50%额外的核心 - 8 核 Zen3 的表现就像 12 核 Zen2 (例如 3900X) - 因此,即使 10 核 10900K 也无法竞争。考虑到你可以只是用现有的 AM4 主板 (需要 BIOS 更新来支持它), 如果从原来的 Zen1/ Zen+ 这是一个巨大的升级, 。
如果你能负担得起——尤其是在这个前所未有的时代——这是一个"不用思考"的升级,基于 AM4 的旧平台还能活很久。您并不需要 PCIe4 及其适度的改进(因此还需要 500 系列的主板)- 无论如何,这需要昂贵的 PCIe4 SSD 和昂贵的 GP-GPU 升级。
考虑到 Zen2 比 Zen® 快 40%(别介意初代 Ryzen),Zen3 实际上比 Zen+ 快 2 倍 — 仅仅两代有96%的性能提升,而核心计数保持不变(与英特尔(Intel)只是增加了核心计数不同)。还要考虑您现在可以获得一个 16 核/32 线程 AM4 CPU(它最初只有 6 核选项),这就像在同一 AM4 插槽中具有 32 核/64 线程 Ryzen - 整体性能提高 5.3 倍。
关于我们唯一能想到的问题是成本的增加,不仅ryzen 3000系列自推出以来价格一直上涨,5000系列的官价也高出50刀,一旦NDA解禁,测评数据出来,并考虑到现货较少和对 IT 设备需求增加,价格很可能飞涨。最好现在购买或预购一个, 以避免抢购失败
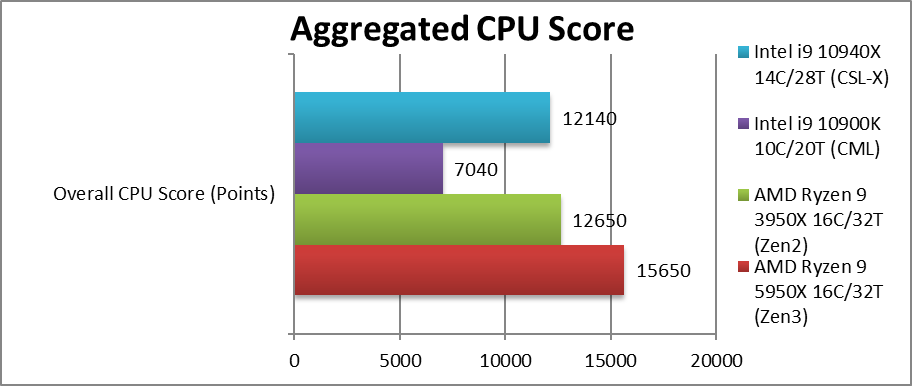
最终篇——5950x
注意:参与的10940x开启avx512进行对比
算法 (arthmetic navie ) +13~25%
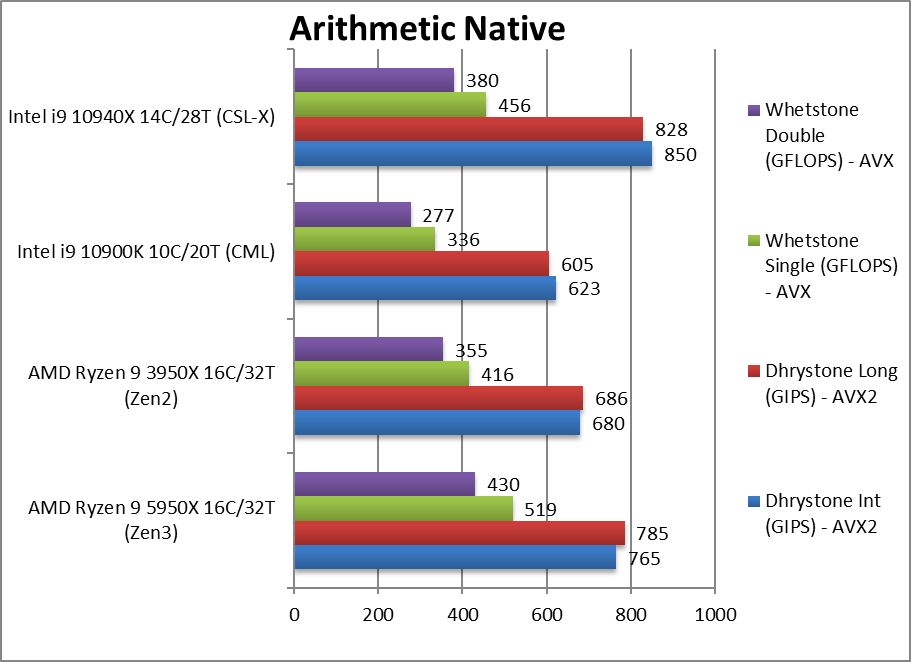
Native Dhrystone Integer (GIPS) 传统整数运算
Native Dhrystone Long (GIPS) 64位整数运算
Native FP32 (Float) Whetstone (GFLOPS) 浮点运算
Native FP64 (Double) Whetstone (GFLOPS) 64位浮点运算
矢量单指令多数据流(vector simd native) +16-37%
Native Integer (Int32) Multi-Media (Mpix/s) 32位整数mm
Native Long (Int64) Multi-Media (Mpix/s) 64位整数mm
Native Quad-Int (Int128) Multi-Media (Mpix/s) 128位整数mm
Native Float/FP32 Multi-Media (Mpix/s) 32位浮点mm
Native Double/FP64 Multi-Media (Mpix/s) 64位浮点mm
Native Quad-Float/FP128 Multi-Media (Mpix/s) 128位浮点mm
SIMD测试中10940x全部开启avx512
加密性能(crypography native) +8%~97%
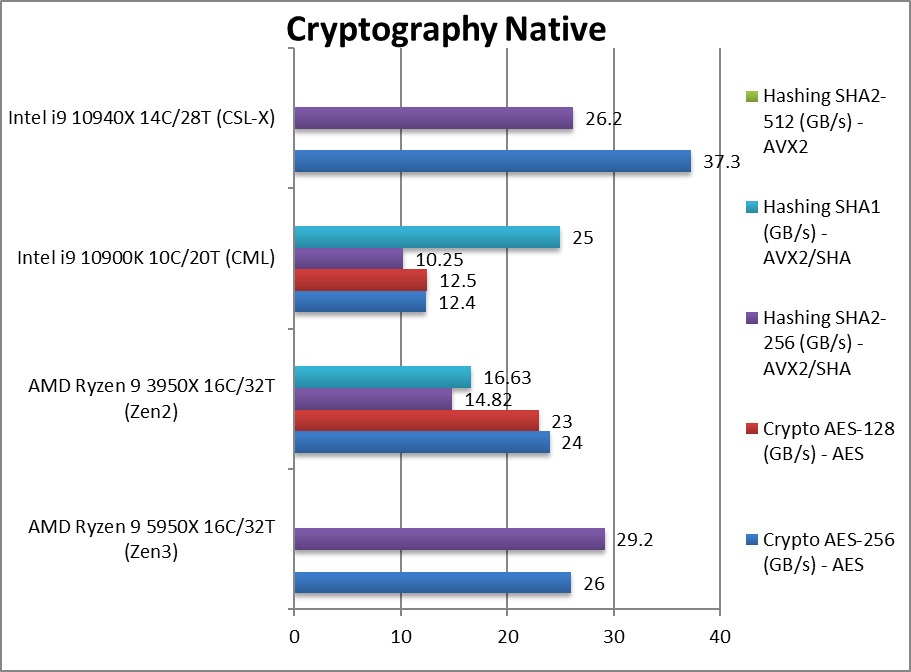
Crypto AES-256 (GB/s) aes256加密
Crypto AES-128 (GB/s) aes128加密
Crypto SHA2-256 (GB/s) sha256加密 (amd使用sha hwa指令,intel使用avx512)
Crypto SHA1 (GB/s) sha1加密
Crypto SHA2-512 (GB/s) sha512加密
加密性能和内存带宽绑定的。新的sha hwa干掉了avx512。测试提到zen3用了更少的内存通道数和更低的内存频率
金融分析 (financial **ysis nativ) -25%~+7%
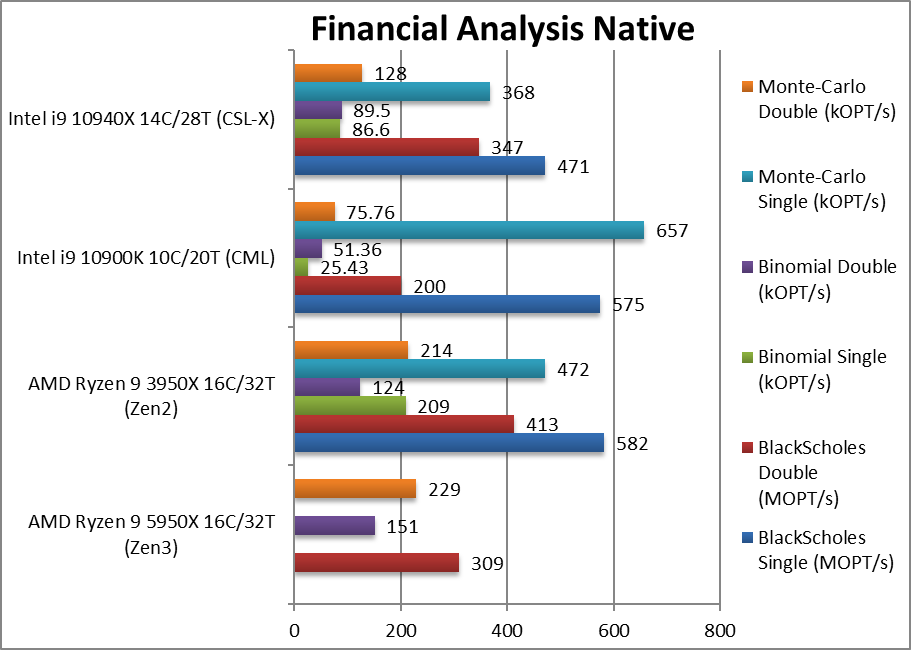
Black-Scholes float/FP32 (MOPT/s) 标准金融运算
Black-Scholes double/FP64 (MOPT/s) FP64代码版本
Binomial float/FP32 (kOPT/s) 二项式使用线程共享的数据,对缓存和内存压力比较大
Binomial double/FP64 (kOPT/s) FP64代码版本
Monte-Carlo float/FP32 (kOPT/s) 蒙特卡洛运算同样使用线程的共享数据,但只读,减少了对缓存写入压力
Monte-Carlo double/FP64 (kOPT/s) FP64代码版本
ryzen在非SIMD的浮点运算表现了总是很好,这里是统治性胜利。我们确实有一些异常值分数, 这可能表示需要我们的软件或 Windows (计划程序) 解决的缩放问题。无论如何,即使是有异常值也表明英特尔的 CML 内核无法与现代 AMD Zen 内核竞争。
科学计算(scientific **ysis native) +12%~68%
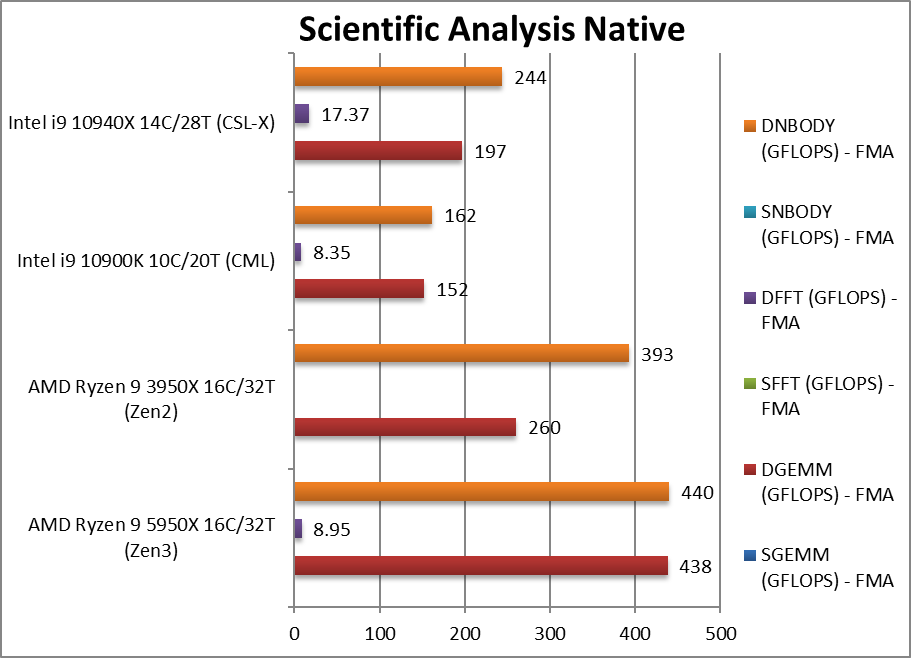
SGEMM (GFLOPS) float/FP32 在这个广泛使用的强向向算法(例如人工智能和机器学习)中。
DGEMM (GFLOPS) double/FP64 FP64代码版本
SFFT (GFLOPS) float/FP32 FFT 也严重矢量化,但强调内存子系统更多。
DFFT (GFLOPS) double/FP64 FP64代码版本
SNBODY (GFLOPS) float/FP32 N-Body 仿真是矢量化的,但内存访问较少。
DNBODY (GFLOPS) double/FP64 FP64代码版本
这个测试10940x全部开启avx512
高度矢量化的 SIMD 代码 Zen3 仍有可显著提高,但内存访问延迟敏感算法(非流式处理)(如 FFT/N-Body)也存在问题。GEMM广泛应用于卷积(例如神经网络AI/ML、图像处理),这里Zen3的速度要快得多。
图像处理(image processing native) +14%~37%
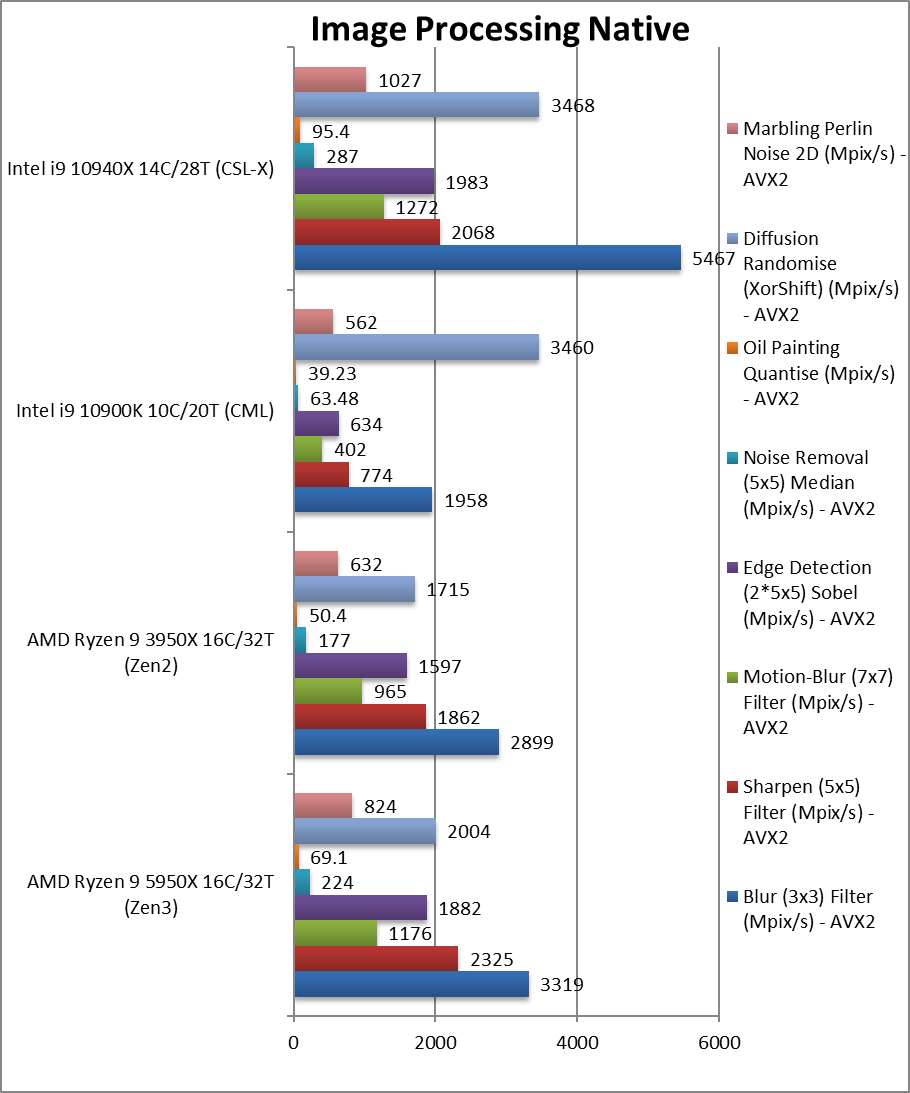
CPU Image Processing Blur (3×3) Filter (MPix/s) 矢量整数运算
Sharpen (5×5) Filter (MPix/s) 同上运算,但是用更多的共享数据
Motion-Blur (7×7) Filter (MPix/s) 同上运算,但是用更加多的共享数据
Edge Detection (2*5×5) Sobel Filter (MPix/s) 不一样的算法,但依旧是矢量化的工况
Noise Removal (5×5) Median Filter (MPix/s) 仍然是矢量代码
Oil Painting Quantise Filter (MPix/s) 这个测试对ryzen构架一直都很难
Diffusion Randomise (XorShift) Filter (MPix/s) 整数运算
Marbling Perlin Noise 2D Filter (MPix/s) 最后一个整数运算工况
这个测试10940x全部开启avx512,由于hedt有4通道,这个测试完美统治
总分(aggregated cpu score) +24% (赢了开启avx512的10940x,但没有它大哥10980x参与)
Executive Summary: Zen3 (16C) is ~24% faster than Zen2 (16C) across all kinds of algorithms. Fastest desktop compute deserves 10/10!
总结,比3950x提升了24%,最快的桌面处理器,10分没悬念
与具有统一 L3 缓存的 8 核 Zen3 设计不同,12/16C Zen3(例如 59XX )仍然具有单独的 L3 缓存,但现在是每8核共享缓存而不是4核。因此,我们认为它会改善一点比Zen2(16C),但并不多。但是,在所有基准测试中,它仍然能跑得更快24%。
这是桌面计算性能的巅峰 - 可用于所有 AM4 接口主板(与 BIOS 更新) - 而无需花费严重的资金在工作站/HEDT 套件。并不是说 5950X (就像之前 3950X) 是 "便宜的", 而是考虑到 HEDT 平台的成本 (例如 ThreadRipper, 英特尔的 2011 接口等), 它价值很好。5950X 功能强大,即使是 AVX512 英特尔高端 CPU 也无法击败它,甚至旧的 ThreadRipper(例如 1950X、2990X)在计算任务中也遭到击败。
关于唯一的问题是,它仍然停留在2通道DDR4内存,即使在高速(例如昂贵的4266Mt/s)不能喂饱16核/32线程的流算法,尽管有绝对庞大的64MBL3缓存。英特尔的 HEDT 平台具有 4 通道 DDR4 + AVX512,能够在这些类型的算法中击败它。
DDR5 不会很快到来, 但这需要一个新的平台 (AM5 套接字) 。这种高端 CPU 还应与良好的主板(例如 X570)与 PCIe4 配对,因为在这里,它可能会有所作为 - 再次喂饱所所有核心。
如果你有钱和需要高端计算性能,不知何故买不起 HEDT 平台,那么这是最好的,你可以得到一个长期一流的平台。
5800x提升是最大的,测评团队给了最高评价,分值增增长也最多,共享L3比我们想象的要强大很多。
5950x提升不如5800x那么多,跨CCD开销还是存在的。也许这就是5800x为什么那么没性价比了。
现在某些玩家的5600x和5900x购买欲可能会下降点,往5800x上倾斜。
最后还得看游戏测评,这篇全部都是cpu生产力性能
|
|


 发表于 2020-10-31 16:14
发表于 2020-10-31 16:14
 虽然5800x性价比是不高……但是如果能到2k5的话……太美了
虽然5800x性价比是不高……但是如果能到2k5的话……太美了 怎么10900k比9900k低这么多,这河里吗
怎么10900k比9900k低这么多,这河里吗