

诚司 发表于 2024-4-22 00:30
所有的榜只能看个大概,并没太大意义,如果硬说有个榜最有用,那应该是 LMSYS Chatbot Arena Leaderboard, ...
王怡人 发表于 2024-4-22 00:50
llama3 70B用了下别人部署的demo, 中文能力还是很拉, 最简单的, 我问中文你直接给我回答中文这点都做不 ...
隐形术的隐形书 发表于 2024-4-22 01:10
但通义千问生成的东西文采好点,文心一言识别可以,但是生成比较保守



 问更有倾向的东西感觉都非常中立,还是说这种部分目前只能这样了。
问更有倾向的东西感觉都非常中立,还是说这种部分目前只能这样了。好much橘 发表于 2024-4-22 03:26
所以现在有哪个值得开会员的吗
这几天才刚开始玩,文心和ChatGPT免费版问一些就业方向上的事情,都 ...
 这么多人吹Qwen我其实没想明白,我用的70b模型,除了对话效果好一点。
这么多人吹Qwen我其实没想明白,我用的70b模型,除了对话效果好一点。
诚司 发表于 2024-4-22 01:16
关键是Qwen有开源版,不但现在有72B,下周据说还有110B开源(现在有demo了),开源模型能调的东西多了去了 ...
flyinsea 发表于 2024-4-22 09:32
请问下70B的个人本地部署不起,7B左右的哪个大模型好点,chatGLM如何?
万恶淫猥手 发表于 2024-4-22 08:22
这么多人吹Qwen我其实没想明白,我用的70b模型,除了对话效果好一点。
但是推理能力和指令遵循能力 ...
诚司 发表于 2024-4-22 10:02
7B没有好的,硬说的话Qwen1.5 7B,纯英文那就llama3,chatglm是一个非常老的baseline,chatglm3也不行,别 ...

诚司 发表于 2024-4-22 10:02
7B没有好的,硬说的话Qwen1.5 7B,纯英文那就llama3,chatglm是一个非常老的baseline,chatglm3也不行,别 ...
x.cat 发表于 2024-4-22 09:22
那么,有没有免费的文心4.0使用呢?
luguozmy 发表于 2024-4-22 11:31
4090可以吗?
。诚司 发表于 2024-4-22 11:39
笔记本版的4090显存只有16g,不太行,台式机的24g显存,大体可以装下qwen 32b,不过我没试过上下文长度多 ...
泰坦失足 发表于 2024-4-22 11:48
https://www.reddit.com/r/LocalLLaMA/comments/1c7owci/running_llama370b_gguf_on_24gig_vram/
量化模 ...

Rushtime33 发表于 2024-4-21 12:59
评测项目怎么还有安全和价值观的,这个怎么量化啊
—— 来自 S1Fun
至于文中这个安全和价值观,那肯定有可以检测的数据集呀( 正经商用软件都有这个要求吧cqc1021 发表于 2024-4-22 01:14
文心一言写机关八股文确实远胜chatgpt
—— 来自 samsung SM-N9860, Android 13上的 S1Next-鹅版 v ...
诚司 发表于 2024-4-22 10:02
7B没有好的,硬说的话Qwen1.5 7B,纯英文那就llama3,chatglm是一个非常老的baseline,chatglm3也不行,别 ...
flyinsea 发表于 2024-4-22 09:32
请问下70B的个人本地部署不起,7B左右的哪个大模型好点,chatGLM如何?
好much橘 发表于 2024-4-21 14:26
所以现在有哪个值得开会员的吗
这几天才刚开始玩,文心和ChatGPT免费版问一些就业方向上的事情,都 ...

好much橘 发表于 2024-4-22 03:26
所以现在有哪个值得开会员的吗
这几天才刚开始玩,文心和ChatGPT免费版问一些就业方向上的事情,都 ...
诚司 发表于 2024-4-22 01:06
llama3和llama2一样,能读中文,但写中文不行
但是从llama3 8B到llama3 70B有一个质变,那就是生产力级别 ...
王怡人 发表于 2024-4-22 20:23
llama3的训练数据里只有5%多一点的内容是非英语的, 里面包含30多种语言, 也就是说中文在训练数据里的 ...
无敌のpeach 发表于 2024-4-22 12:47
70b跑4bit量化最低两张2080ti矿
所以泥潭有没有AI讨论群?经常在其他群看到用弱智吧问题或者各种没有实际 ...
x.cat 发表于 2024-4-22 09:22
那么,有没有免费的文心4.0使用呢?
泰坦失足 发表于 2024-4-22 11:48
https://www.reddit.com/r/LocalLLaMA/comments/1c7owci/running_llama370b_gguf_on_24gig_vram/
量化模 ...
约瑟夫海顿 发表于 2024-4-22 13:02
清华啊,怎么不评估一下清华自己的
----发送自 STAGE1 App for Android.
saya1892 发表于 2024-4-23 00:32
「人类对齐能力」是什么意思
万恶淫猥手 发表于 2024-4-22 22:19
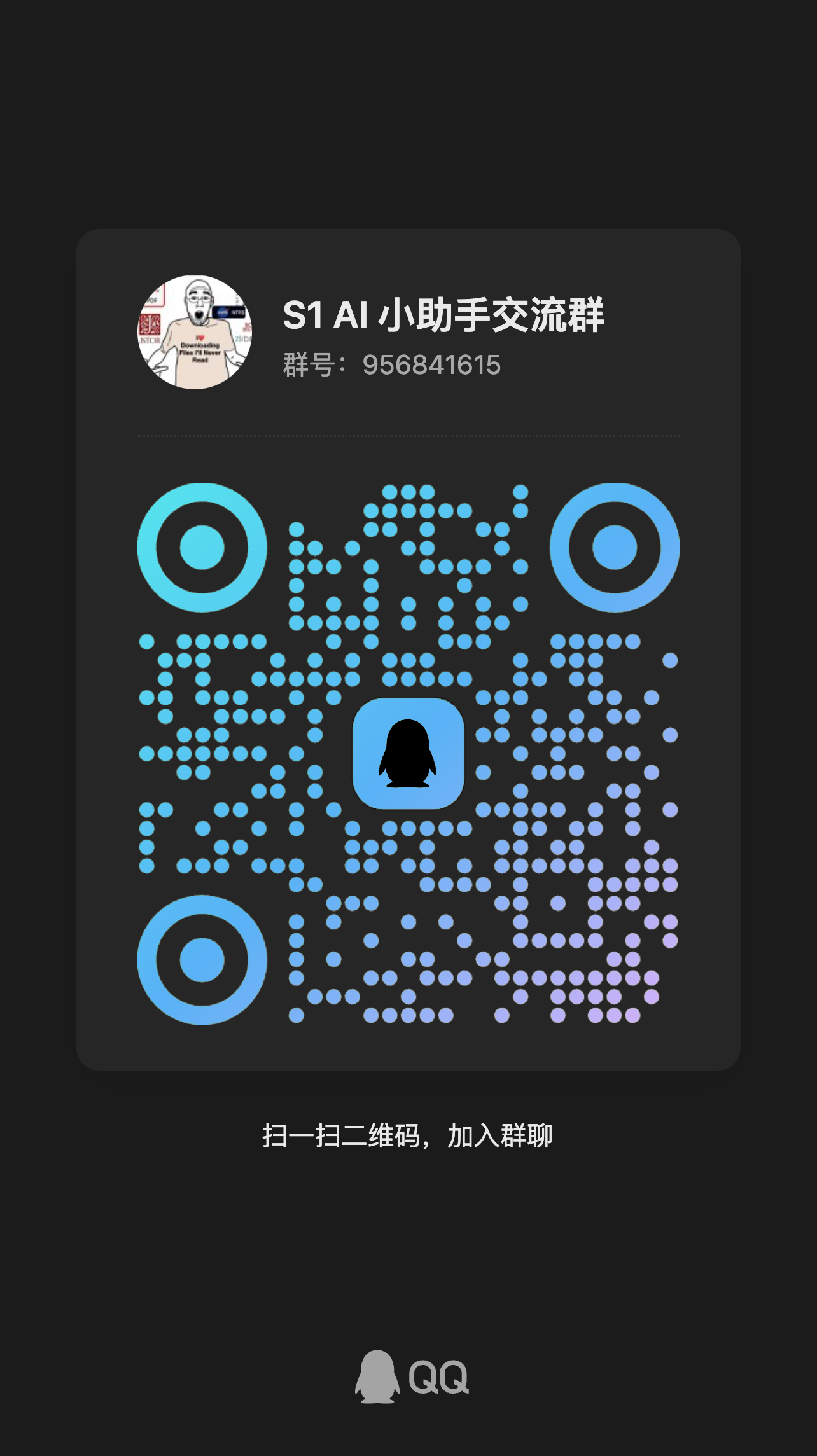
没有的话就直接建一个呗
AI 小助手群,讨论一下 AI 开发和应用 群号 956841615 ...
王怡人 发表于 2024-4-23 01:24
这群号搜不到啊
诚司 发表于 2024-4-22 10:02
7B没有好的,硬说的话Qwen1.5 7B,纯英文那就llama3,chatglm是一个非常老的baseline,chatglm3也不行,别 ...
lzchen 发表于 2024-4-23 01:32
大神,刚好借地问一个小问题,现在手头有一个小项目,甲方有一个4090的机器和一个两张a100的机器,想在上 ...
诚司 发表于 2024-4-23 02:48
应该有n种方法……光盘装好显卡驱动,docker肯定是最保险的……
单卡的话最简单是koboldcpp,windows就单 ...
千千千千鸟 发表于 2024-4-23 03:45
文心一言能做标书吗?
就照着招标文件上的123要求,内容不用管实际情况,胡诌能写的出符合要求的东西不,就 ...
唐泽 发表于 2024-4-23 05:22
借楼问下车轱辘讲话稿这种废话WPS和文心谁强点?因为开了WPS会员一直用的WPS,但是写超过1000字完全不行 ...
lzchen 发表于 2024-4-23 08:23
WPS用的GLM4,跟文心4在这轱辘话上感觉差不多,逻辑强点,文采弱点。超过1000字的东西,你最好给他一个纲 ...
万恶淫猥手 发表于 2024-4-22 22:19
没有的话就直接建一个呗
AI 小助手群,讨论一下 AI 开发和应用 群号 956841615 ...
唐泽 发表于 2024-4-23 08:52
那就将就着用吧……没啥数据,都是纯纯车轱辘话,还以为文心能直接写个两千来字……主要我单位主业比较偏 ...
xihaooo 发表于 2024-4-23 09:43
什么就文心一言那样的辣鸡也配中文理解第一?
有个古诗后面几句我忘了,写了上句问文心一言后面是什么,他 ...
xihaooo 发表于 2024-4-23 09:43
什么就文心一言那样的辣鸡也配中文理解第一?
有个古诗后面几句我忘了,写了上句问文心一言后面是什么,他 ...
诚司 发表于 2024-4-23 02:48
应该有n种方法……光盘装好显卡驱动,docker肯定是最保险的……
单卡的话最简单是koboldcpp,windows就单 ...
cqc1021 发表于 2024-4-22 01:14
文心一言写机关八股文确实远胜chatgpt
—— 来自 samsung SM-N9860, Android 13上的 S1Next-鹅版 v ...
lzchen 发表于 2024-4-23 10:08
大佬,最近有没有llama3的gguf模型哈?找了一大圈也没发现哪可以下,不是说开源了么。 ...
xiaoleirei 发表于 2024-4-23 10:12
怎么喂词能把八股文的字数拉长?句型总是差不多,概述-各个细项-总结,每段2~3行的样子 ...
原来WPSAI用的是GLM-4?之前免费测试阶段感觉拉得一批啊,简直废话文学大师酱狐狸 发表于 2024-4-23 10:41
原来WPSAI用的是GLM-4?之前免费测试阶段感觉拉得一批啊,简直废话文学大师 ...
诚司 发表于 2024-4-23 10:37
https://huggingface.co/MaziyarPanahi/Meta-Llama-3-70B-Instruct-GGUF
huggingface搜索的问题,你搜lla ...
 ,以前不关注国外的模型,最近赶鸭子上架了才临时抱佛脚。。。话说抱抱脸下载是真的慢啊
,以前不关注国外的模型,最近赶鸭子上架了才临时抱佛脚。。。话说抱抱脸下载是真的慢啊 。
。lzchen 发表于 2024-4-23 11:00
原来如此,以前不关注国外的模型,最近赶鸭子上架了才临时抱佛脚。。。话说抱抱脸下载是真的慢啊[ ...
Lisylfn 发表于 2024-4-23 09:48
免费和付费是不一样的
xihaooo 发表于 2024-4-23 11:16
排名快垫底的通义千问也没这么玩,百度的下限在哪?
feve9999 发表于 2024-4-22 08:30
写网文战斗场景哪个好。
约瑟夫海顿 发表于 2024-4-22 13:02
清华啊,怎么不评估一下清华自己的
----发送自 STAGE1 App for Android.
万恶淫猥手 发表于 2024-4-22 22:19
没有的话就直接建一个呗
AI 小助手群,讨论一下 AI 开发和应用 群号 956841615 ...
王怡人 发表于 2024-4-23 00:49
就是道德观价值观表现得更像人, 以免被犯罪分子利用或者产生不良的引导, 比如没对齐之前你让AI教你如何当 ...
 那我要这AI有何用!AI应当提供人类想要获取的而他知道的任意知识
那我要这AI有何用!AI应当提供人类想要获取的而他知道的任意知识xiaoleirei 发表于 2024-4-23 10:12
怎么喂词能把八股文的字数拉长?句型总是差不多,概述-各个细项-总结,每段2~3行的样子 ...
lzchen 发表于 2024-4-23 09:32
这种就要你把相关资料放在提示词里面,让他去仿写了。我一般附带2-3篇例文和基本提纲(提纲其实也可以生 ...
英文场景使用多的可以赶紧申请一个groq api,直接白嫖llama3-70b,800 tokens/s真的有香到kuleisite1992 发表于 2024-4-23 12:47
文心的东西今天刚害得我被罚了半年绩效。各位用ai的时候还是要注意一下。出的党建文章可能在网上是有一模一 ...
lzchen 发表于 2024-4-23 11:00
原来如此,以前不关注国外的模型,最近赶鸭子上架了才临时抱佛脚。。。话说抱抱脸下载是真的慢啊[ ...
万恶淫猥手 发表于 2024-4-23 17:09
我的问题,忘记开群号搜索了 @王怡人 @无敌のpeach @hyde_caesar
| 欢迎光临 Stage1st (https://bbs.saraba1st.com/2b/) | Powered by Discuz! X3.5 |